Effective Reinforcement Learning Through Evolutionary Surrogate-Assisted Prescription (Intro Video)
In sequential decision making, the agent interacts with the environment dynamically in a loop of observation and action. at some point after a series of actions, its performance can be measured. For instance, controlling a vehicle, navigating through an environment, playing a board game or a video game, trading stocks, and managing an inventory or making marketing decisions can be seen as sequential decision tasks.
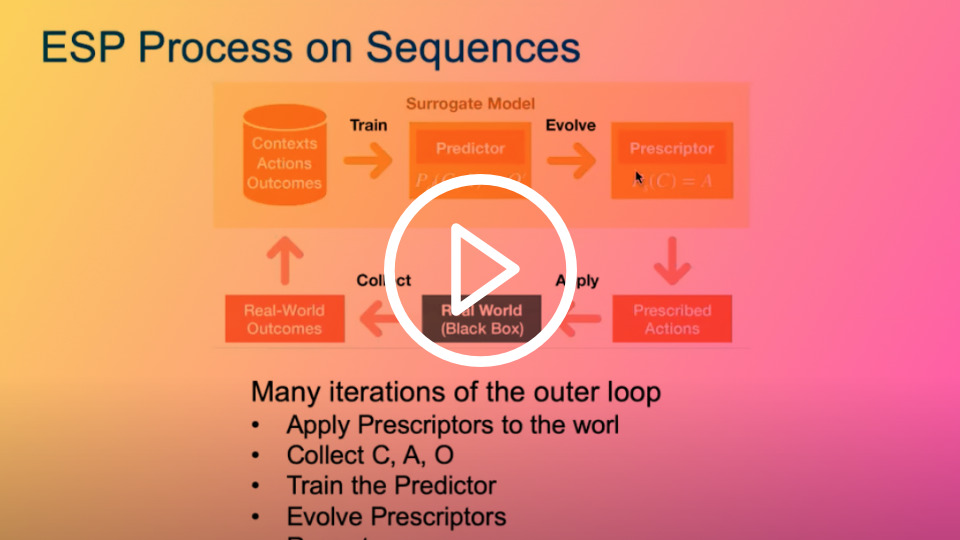
ESP can be applied to sequential decision tasks by extending the contexts and actions to sequences. The Prescriptor can be seen as an RL agent, taking the current context as input, and deciding what actions to perform in each time step. The output of the Predictor, can be seen as the reward vector for that step, i.e. as Q values. Evolution thus aims to maximize the predicted reward, or minimize the regret, throughout the sequence.
As described in Paper 1, the ESP approach to sequential decision tasks was implemented in three domains: (1) function approximation, which makes it easy to visualize the learning process; (2) cart-pole domain, which make is easy to compare with other reinforcement learning methods; and (3) flappy bird domain, illustrating how the Predictor can serve to regularize the solutions.
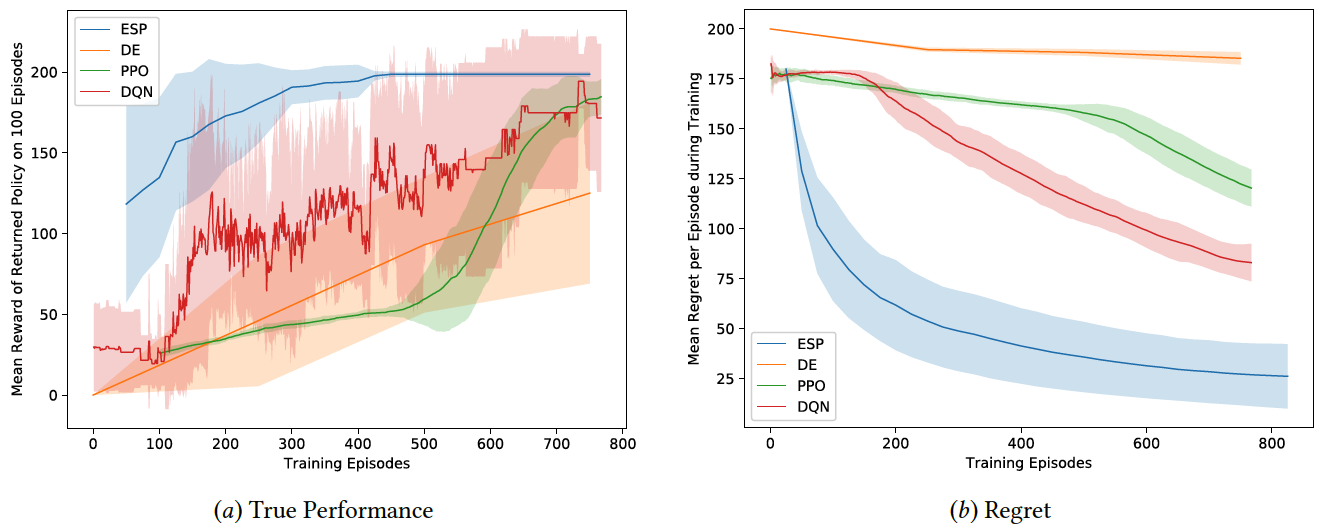
The results are similar in all three domains: Compared to direct evolution and standard reinforcement learning methods PPO and DQN, ESP learns better solutions, learns faster, has lower variance, and lower regret. In other words, it is more sample-efficient, reliable, and safe. The figure below quantifies these conclusions for the cartpole domain. See Demo 1.1 for a visualization in function approximation, and Demo 1.2 for illustration of behavior in the flappy bird domain.