This demo illustrates the Omniglot multi-alphabet character recognition task, and compares the behavior of the CMTR (Coevolved Modules and Task Routing) multitask approach with that of single-task learning. You can explore these models interactively: Draw a character in the box below and see how well each model believes it matches a (lower-case) character in each of the twenty alphabets!
Please draw any lower-case character:
What’s going on?
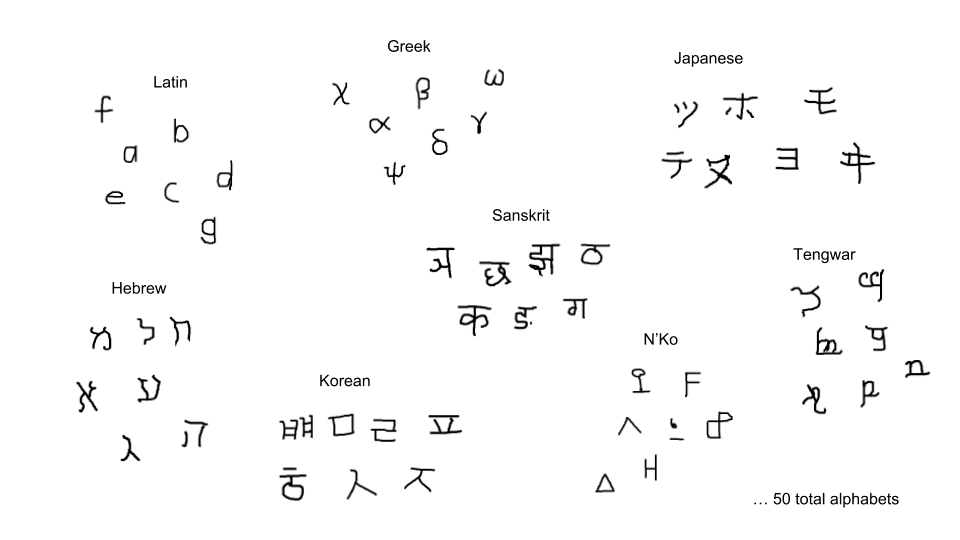
The Omniglot task contains 50 alphabets (most natural, some artificial), 20 of which were used in this demo. As you can see from the sample below, the alphabets have different perceptual characteristics, which makes the tasks of recognizing one set different but related to the others. Therefore, learning them all simultaneously helps learning in each one—which is the main promise of multitask learning. This effect is especially important when there is only a very small amount of training data available for each task, which is indeed the case in Omniglot. In many real world applications, labeled data is expensive or dangerous to acquire (e.g., medical applications, agriculture, and robotic rescue), hence automatically designing models that exploit the relationships to similar or related datasets could, in a way, substitute the missing dataset and boost research capabilities. It is also an excellent demonstration of the power of neuroevolution: There are many ways in which the languages can be related, and evolution discovers the best ways to tie their learning together.
As described in Paper 1, the CMTR method achieved the best performance in our experiments. It improved the state-of-the art in the Omniglot task from 32% error to 10%, and performed much better than learning each task separately. CMTR combines the CMSR (Demo 1.1) and CTR (Demo 1.2) methods: Modules are evolved in subpopulations (as in CMSR), and different topologies are evolved for the different tasks (as in CTR). Each topology utilizes the evolved modules, which are therefore shared across tasks. For this demo, the CMTR method was trained with all 20 tasks simultaneously; also 20 single-task models were trained separately with each of the 20 alphabets.
In the demo, the character that you draw in the box is input to each model, and it finds the best match in each alphabet, according to its training. That is, when a model for an alphabet returns a prediction, it is answering the question “if the drawn character were in my alphabet, which character would it be?” Each image shown is a representative example of the character each model predicts, together with a confidence bar (on the right) and confidence number (above) that indicates how good the match is. The multitask confidence takes into account consistency with other alphabets, whereas single-task confidence measures it in isolation, so the confidence numbers are not compatible. It may take a while to calculate all these matches, so be patient!
Try drawing different characters in different ways to explore how the models perform. Three kinds of observations can be made on this demo: (1) How do the alphabets differ? There are many similar characters, but also meaningful differences. Can you find universal characters, and unique characters? (2) How are the matches made? There are only 15-55 characters in each alphabet, so sometimes there is no good match to the one you draw. The model returns the closest one, in a sense assuming that you tried to draw that character but distorted it in some way. Is it recognizing a specific part of the character that matches well, or perhaps the overall shape? (3) How does the multitask model improve upon the single-task models? Taking the set of predictions as a whole, can you identify the salient relationships between alphabets that evolutionary multitask learning exploits? For instance, since there are many “x”-like characters in many alphabets, does it make recognition of “x” more robust?