The CoDeepNEAT method for evolving modular deep learning architectures is the starting point for CMSR (Coevolution of Modules and Shared Routing), described in Paper 1. Like CoDeepNEAT, CMSR consists of two coevolutionary processes: (1) evolution of modules, i.e. compact deep learning network structures that consist of multiple different layers and pathways, and (2) evolution of network blueprints, i.e. graphs that indicate which modules are used where in the full network. The modules are evolved in separate subpopulations, and each node in the blueprint genotype points to one module subpopulation. The actual network is formed by placing the appropriate modules into each node in the blueprint. In CMSR, each node in the blueprint further has a flag that indicates whether node should be shared or not. If two nodes point at the same subpopulation and if both nodes have the sharing flag turned on, then the two modules are constrained to share weights; otherwise they learn different weights. The same full network is trained with gradient descent to perform all tasks; it has a separate dense output layer for each task.
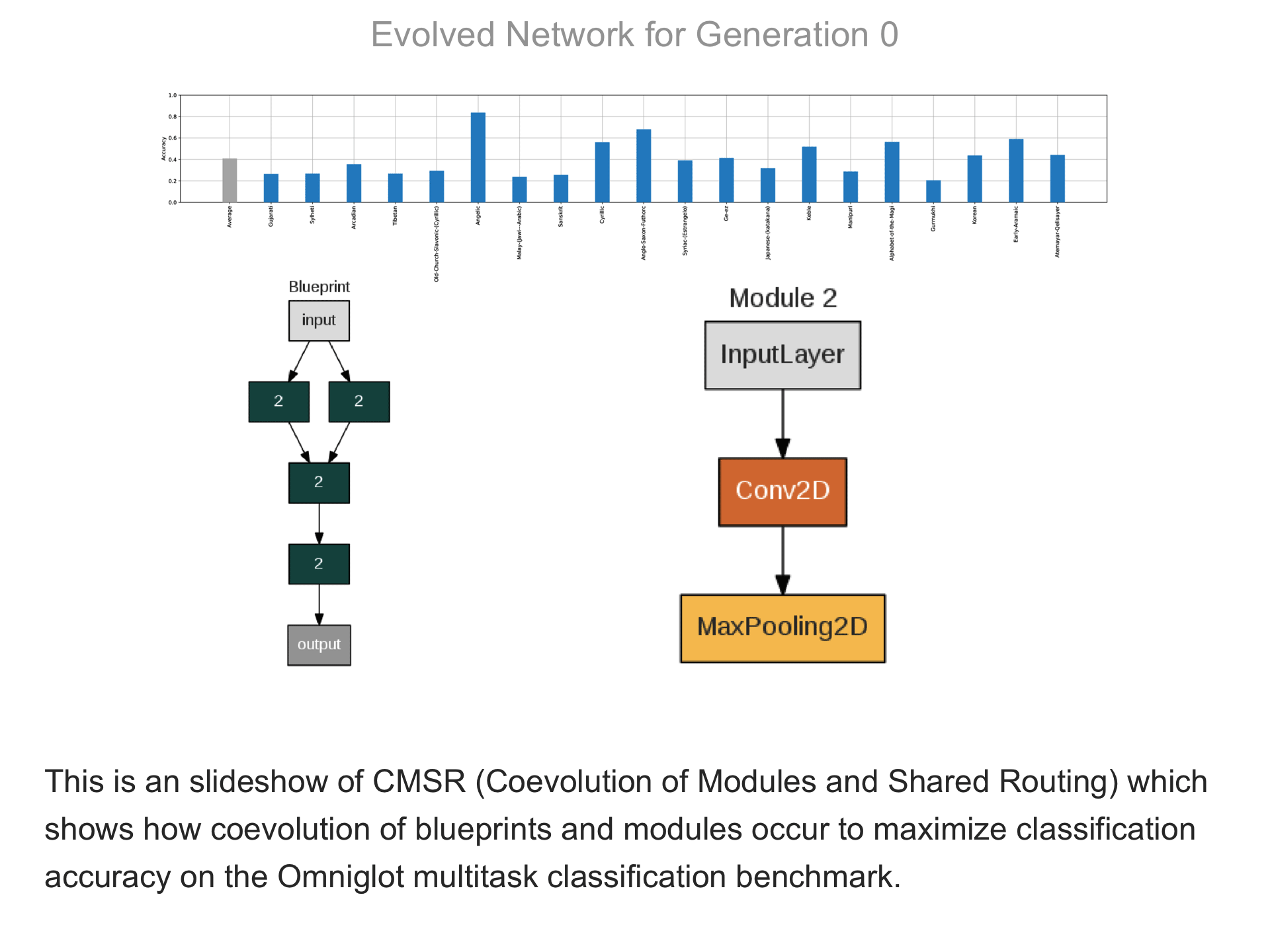
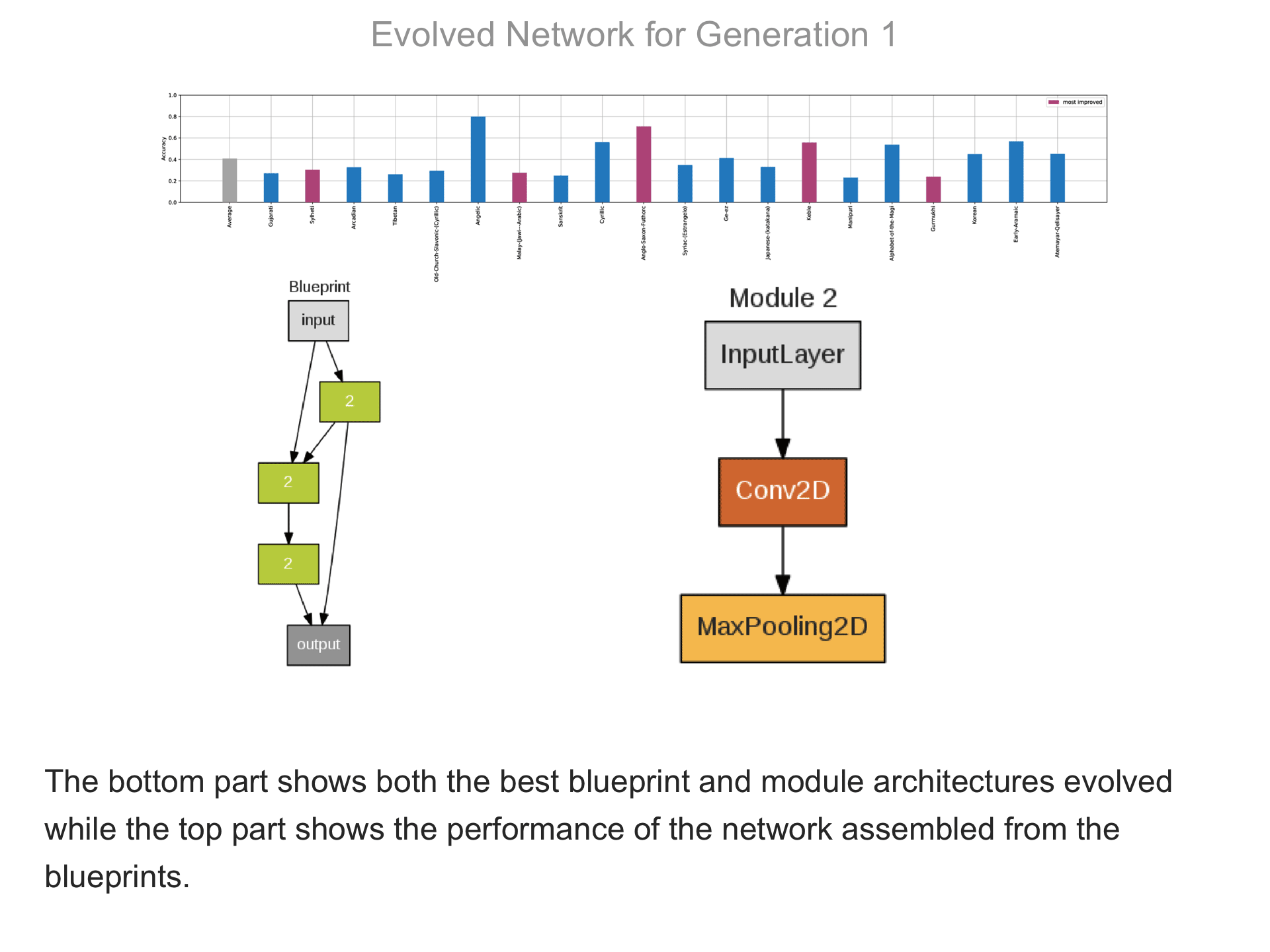
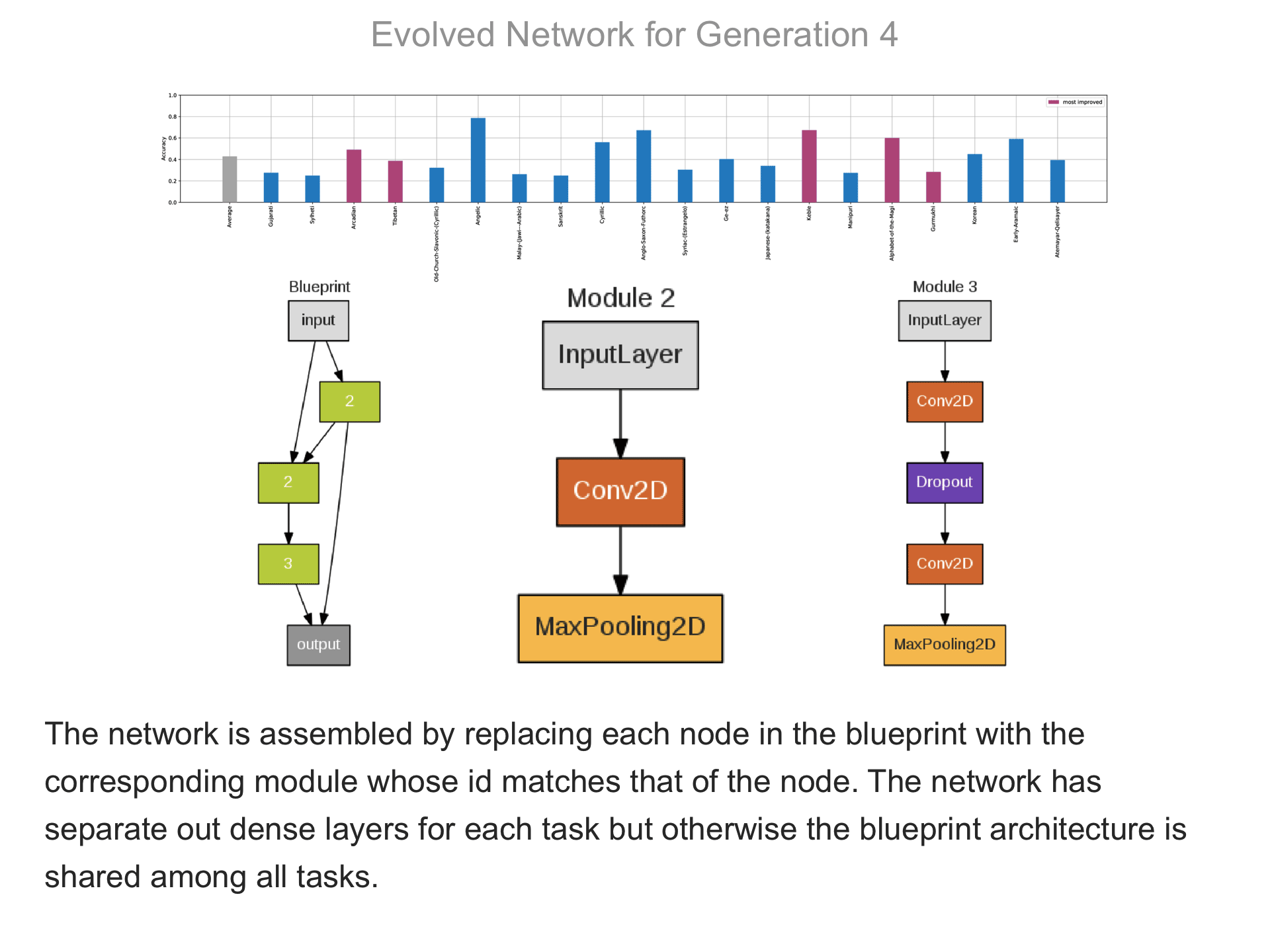
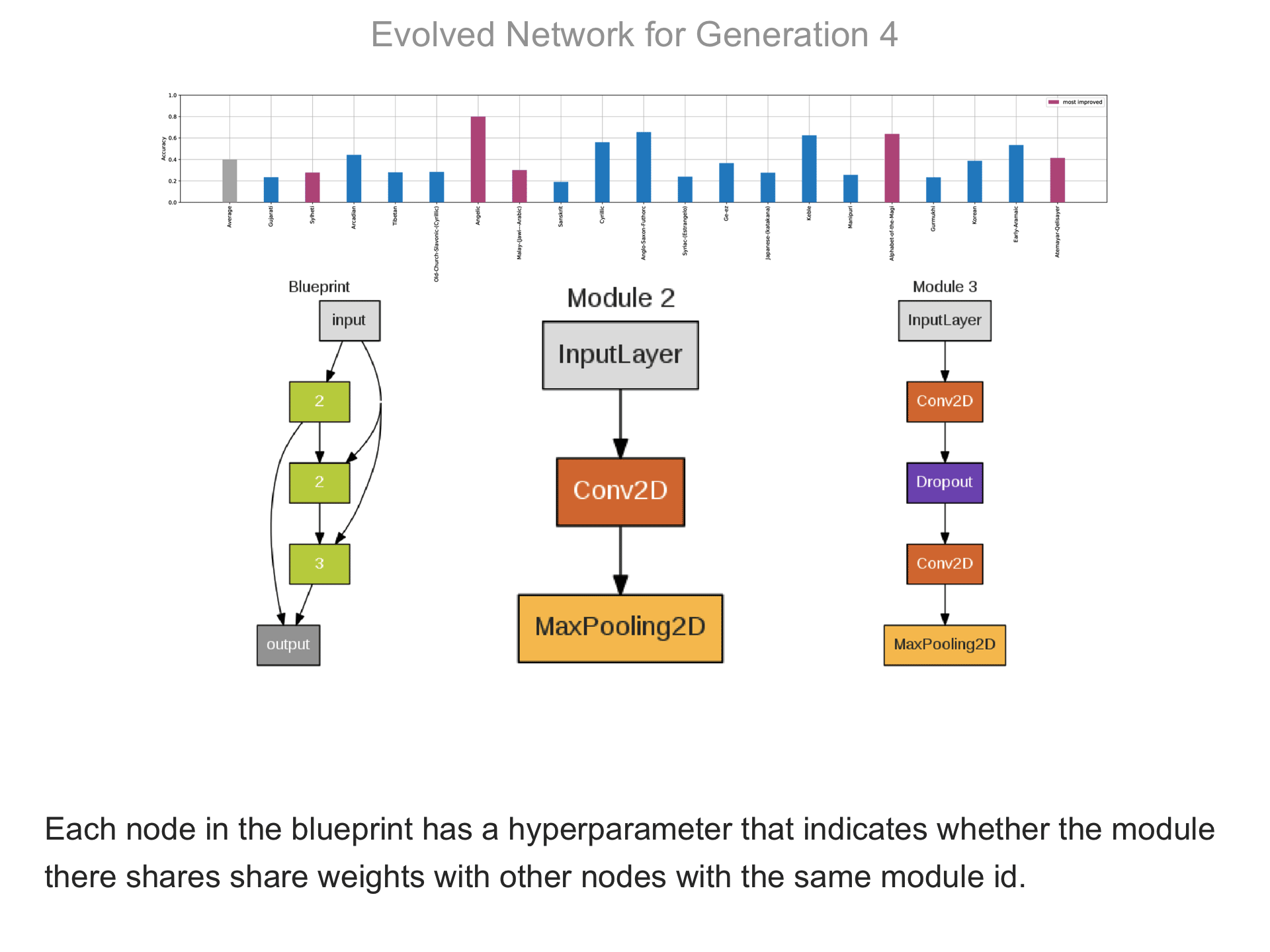
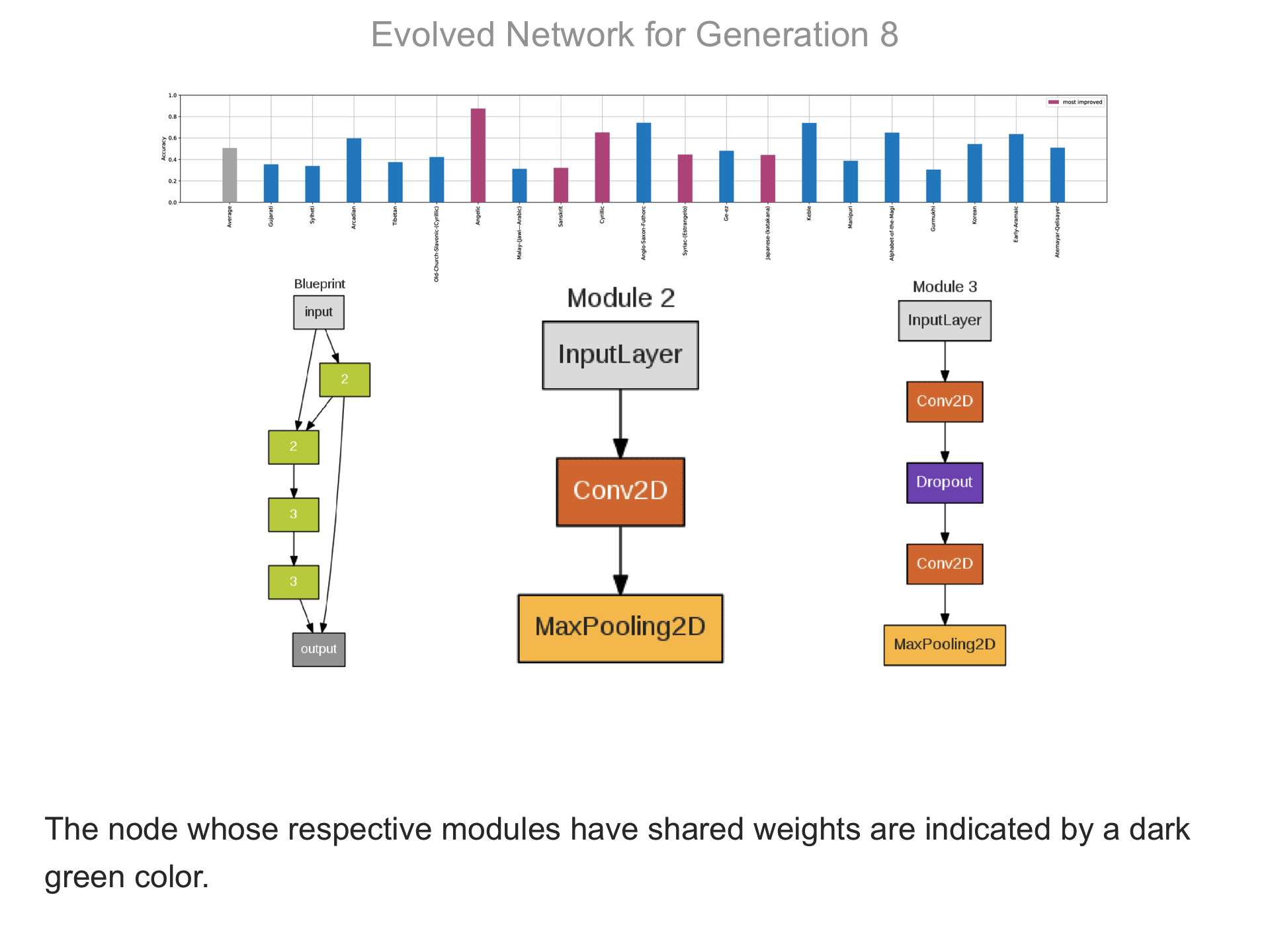
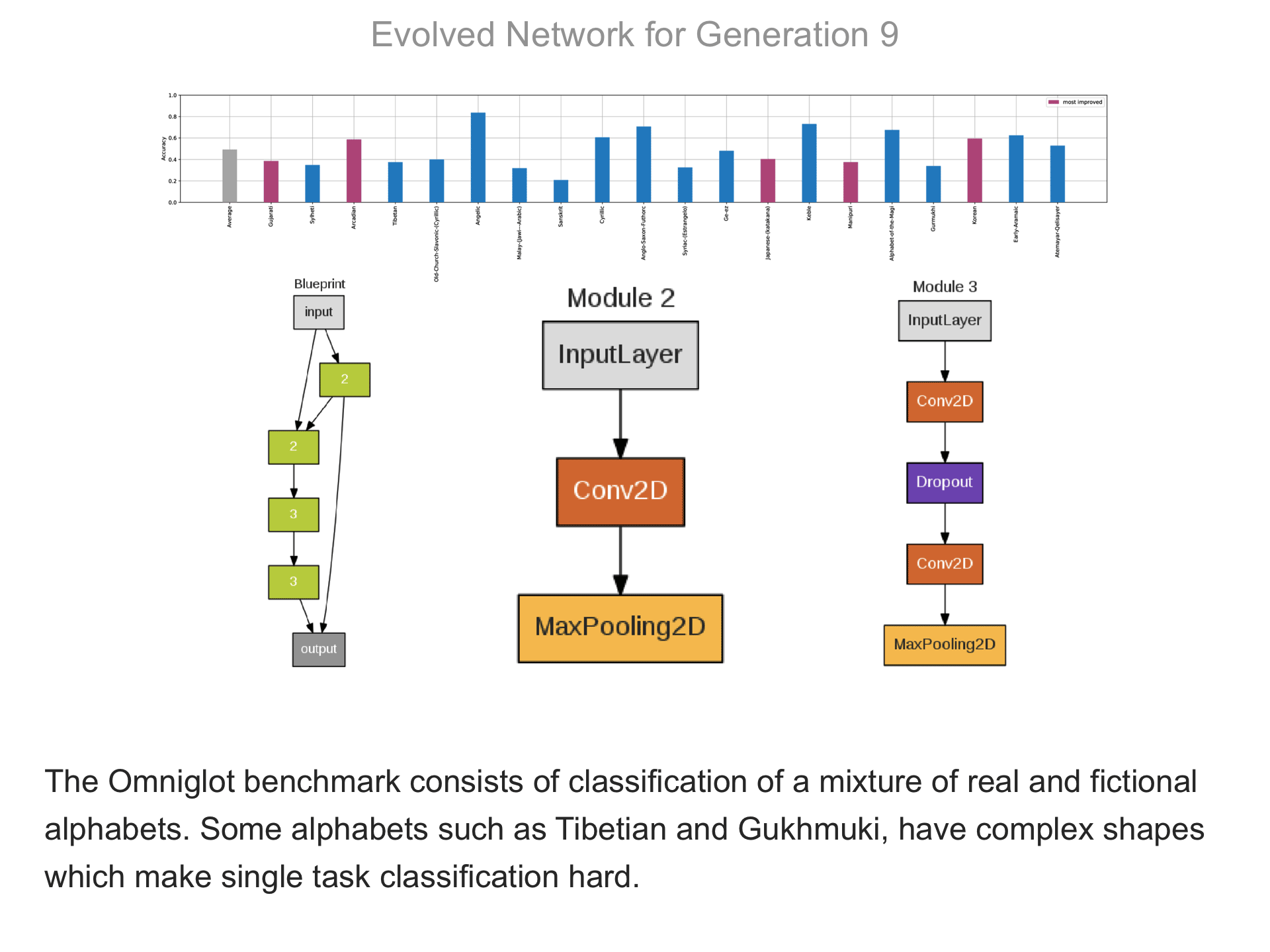
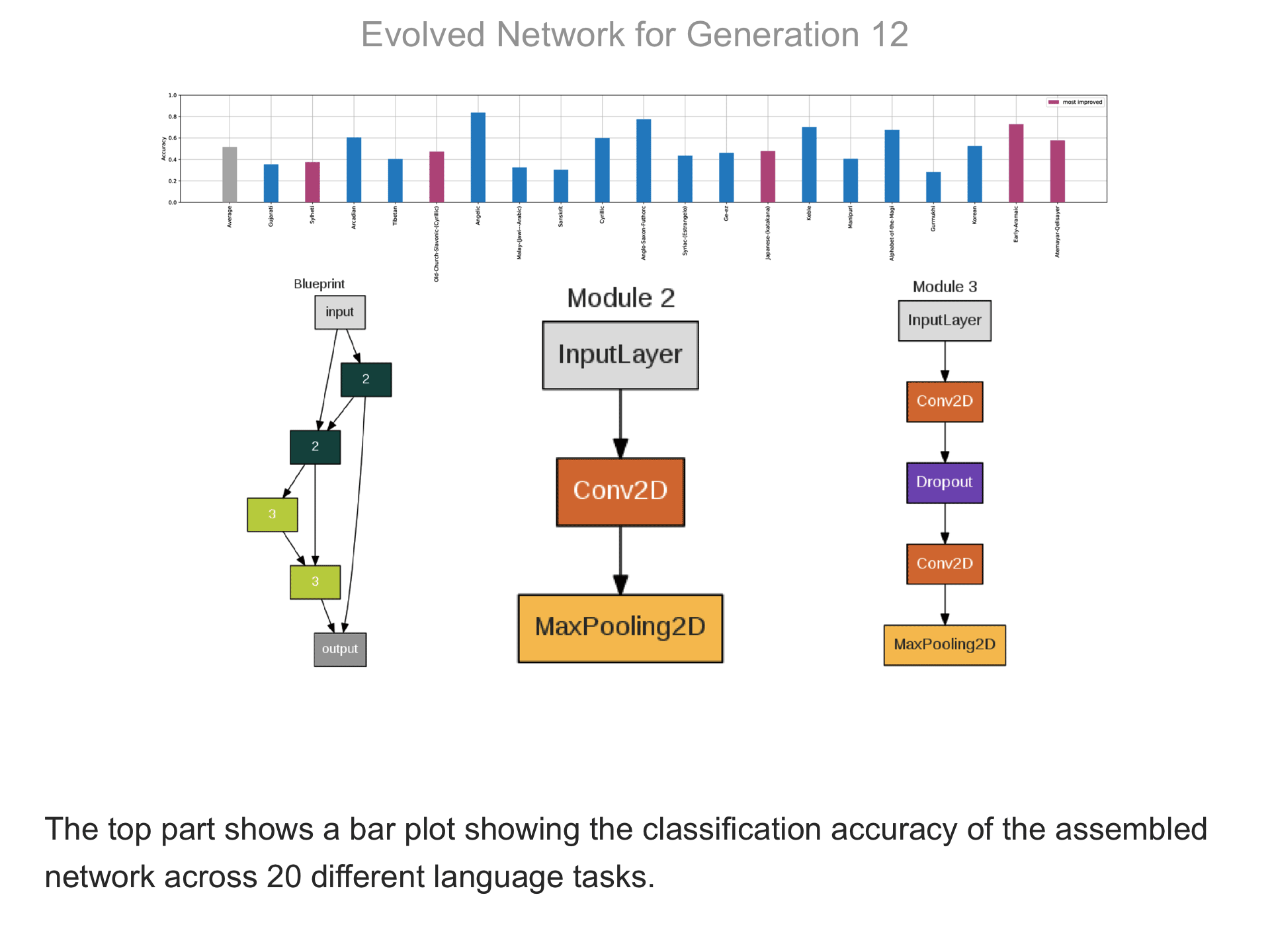
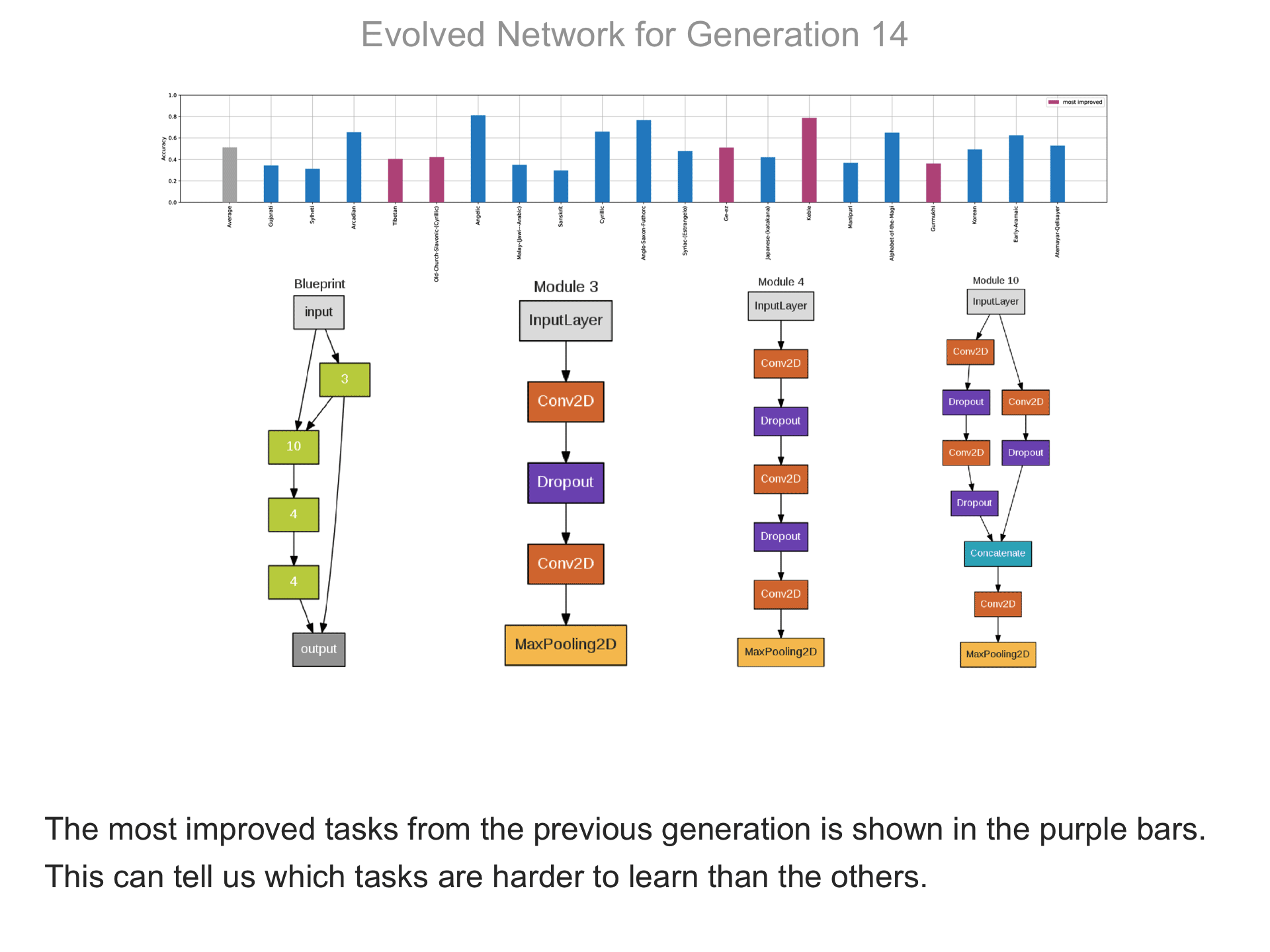
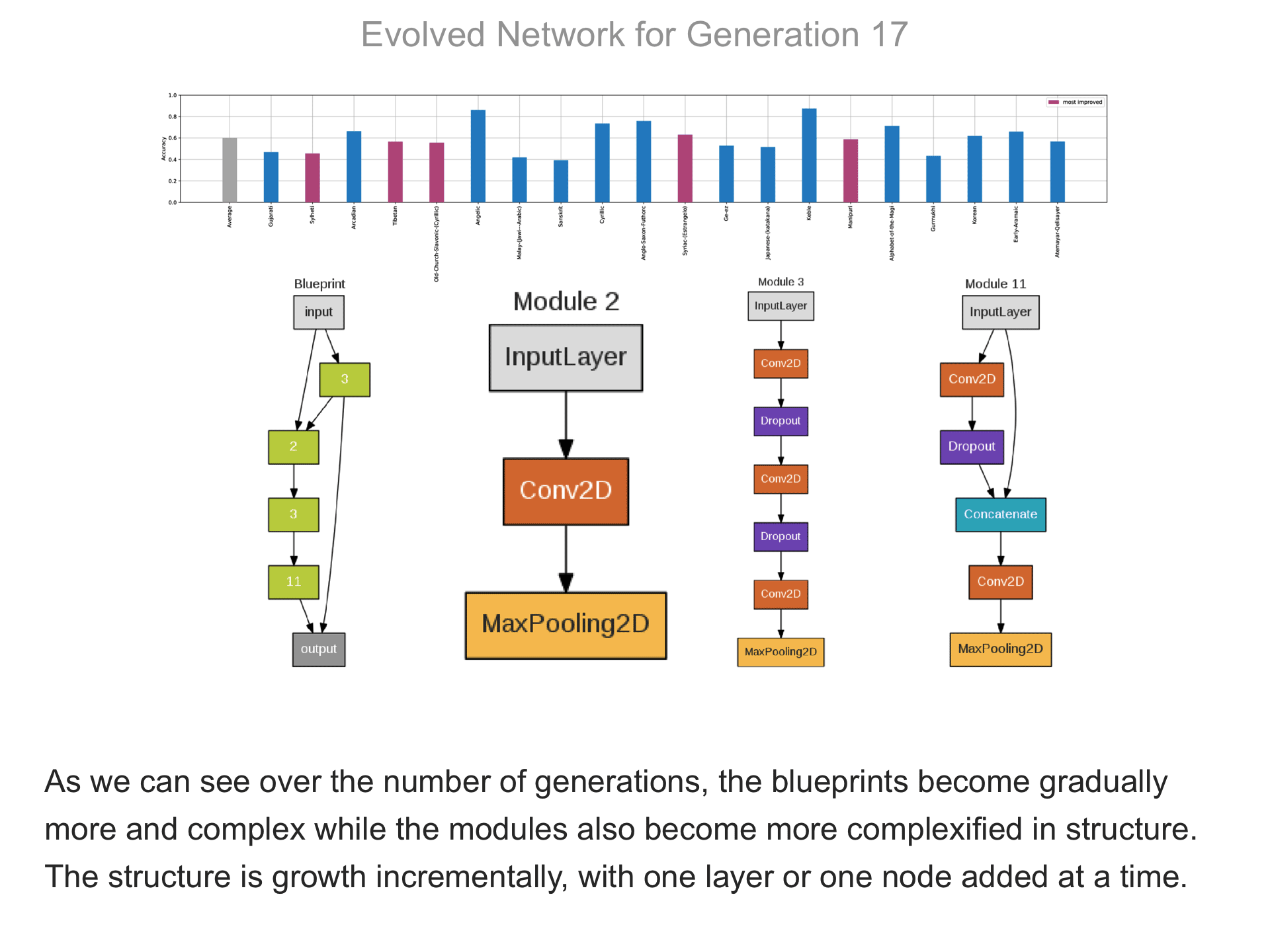
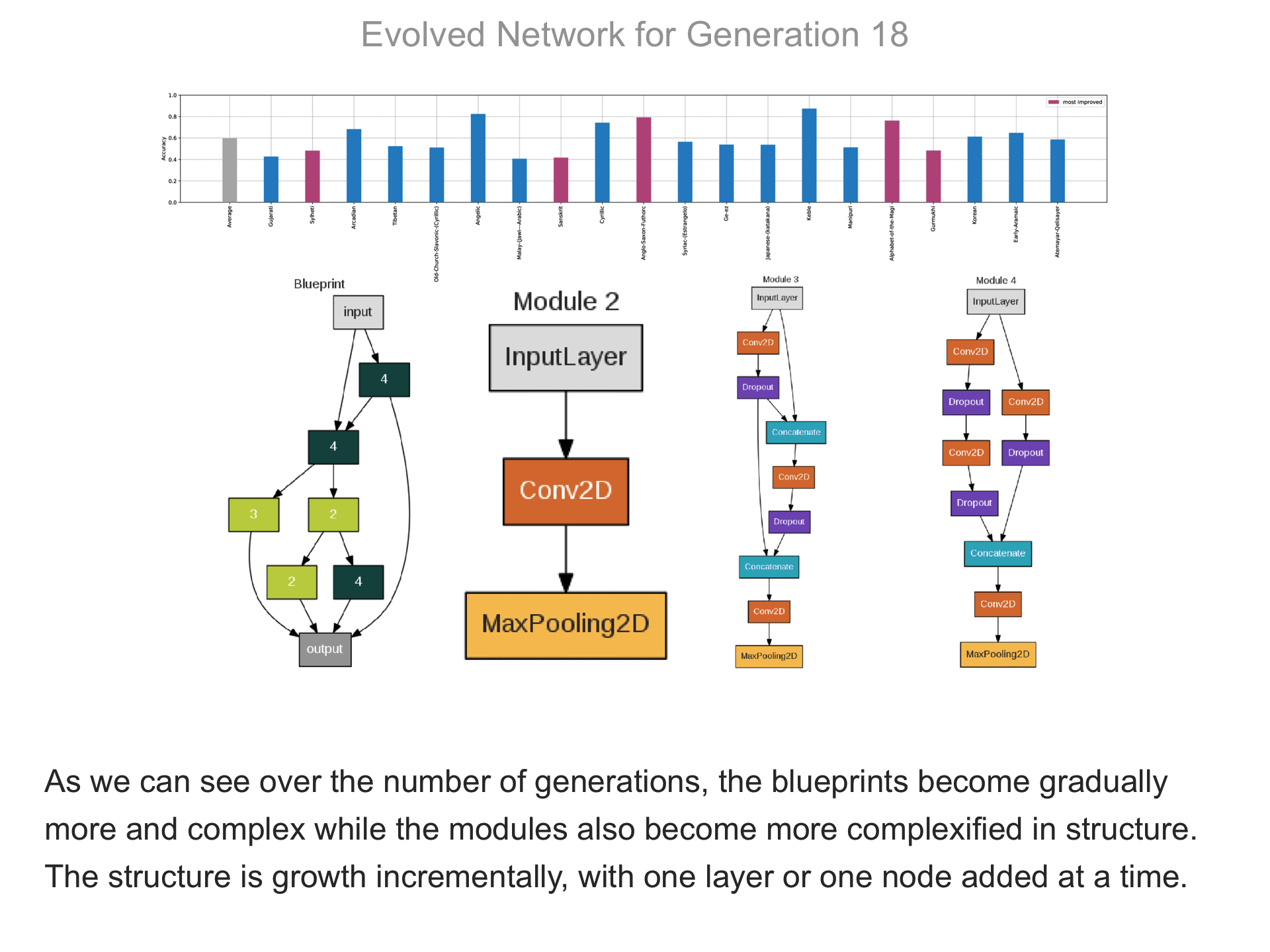
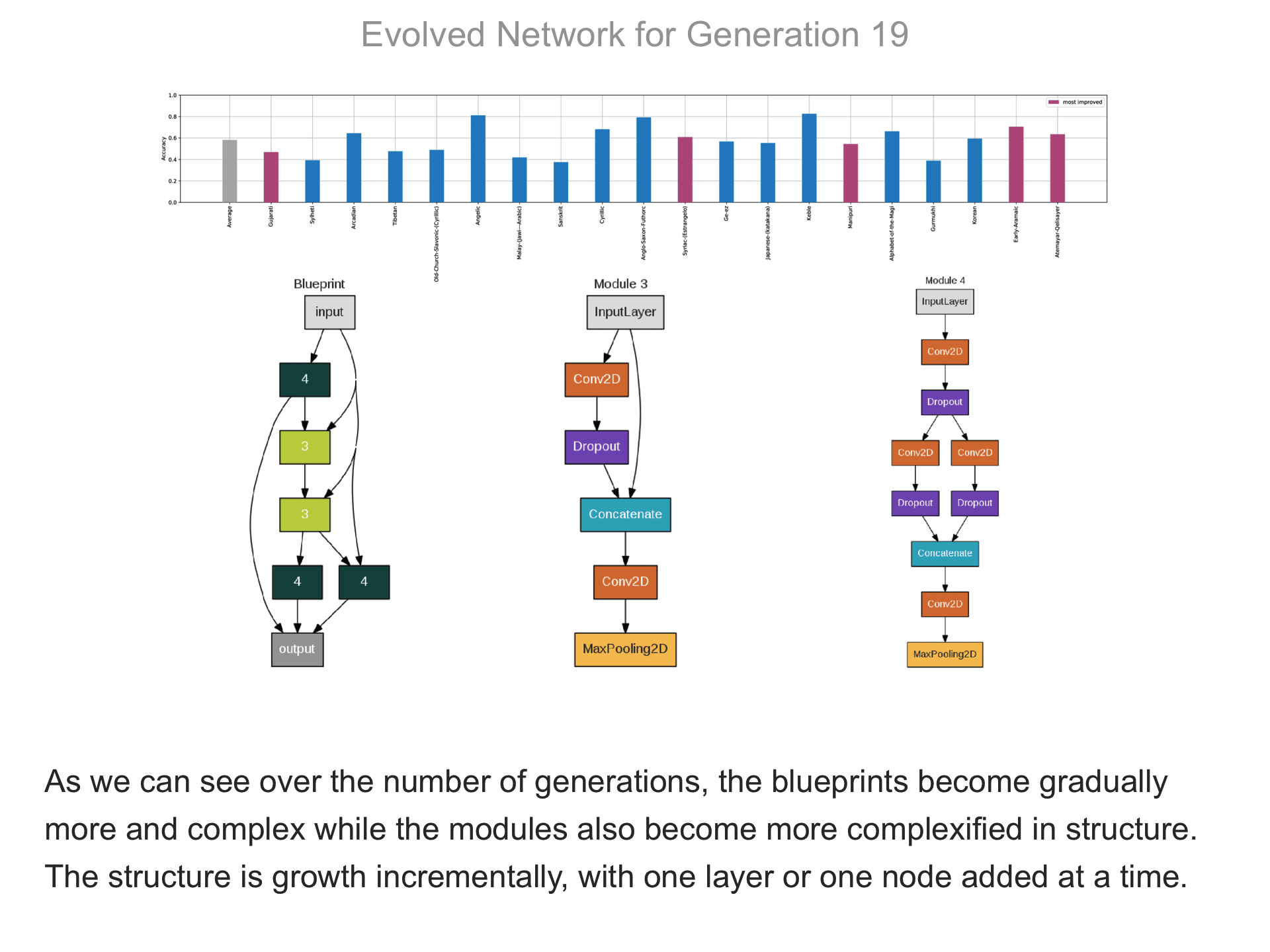
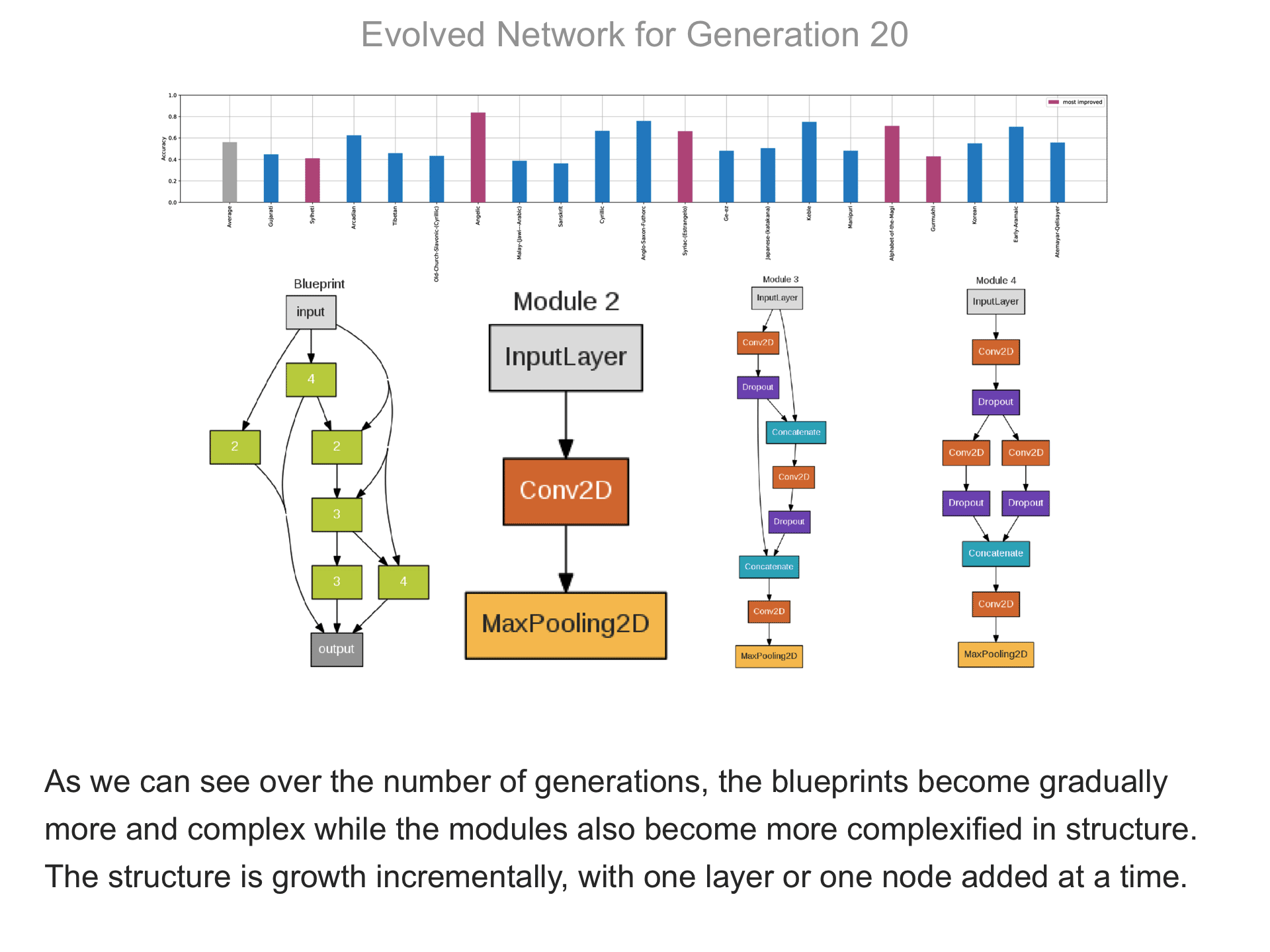
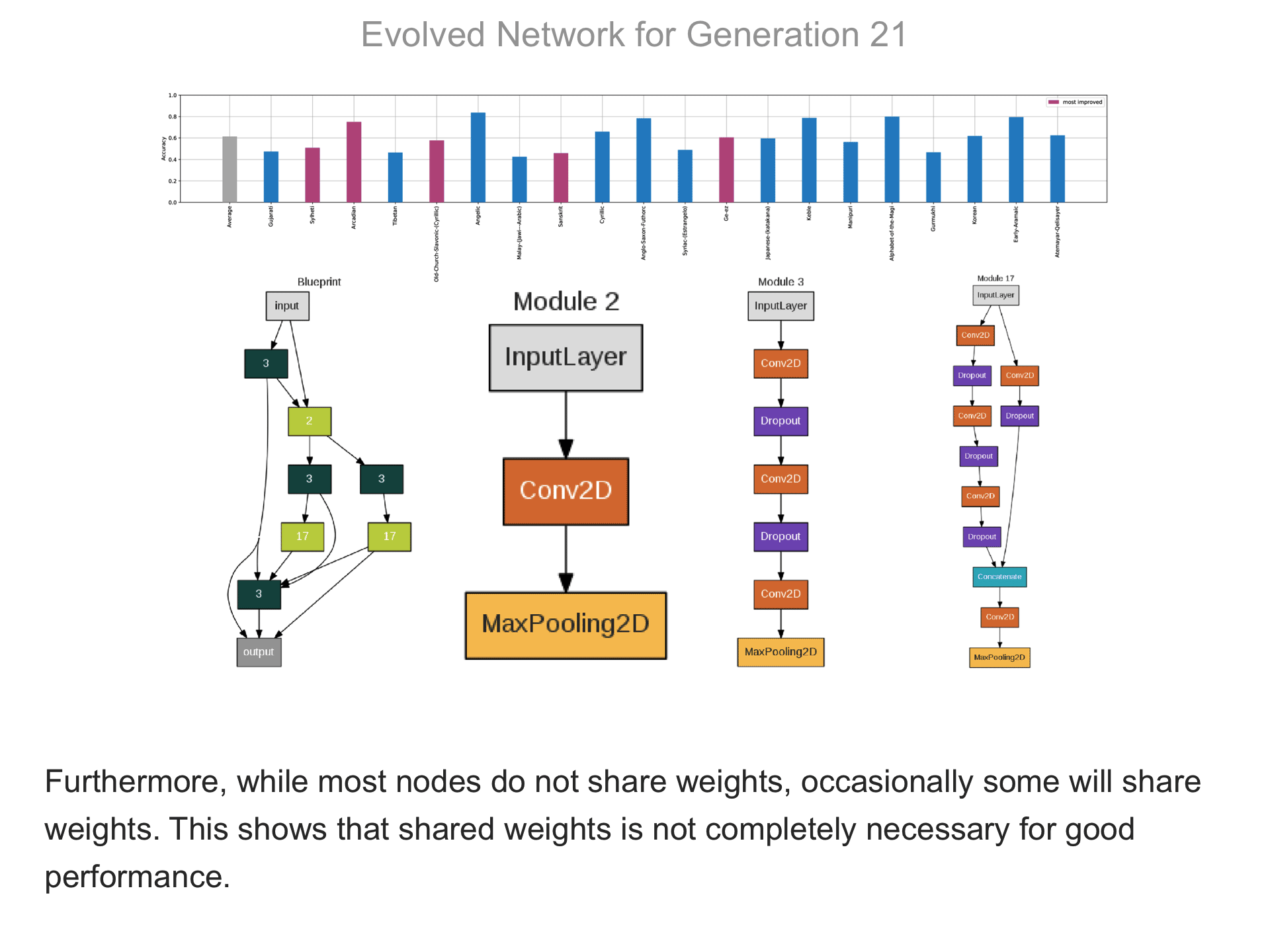
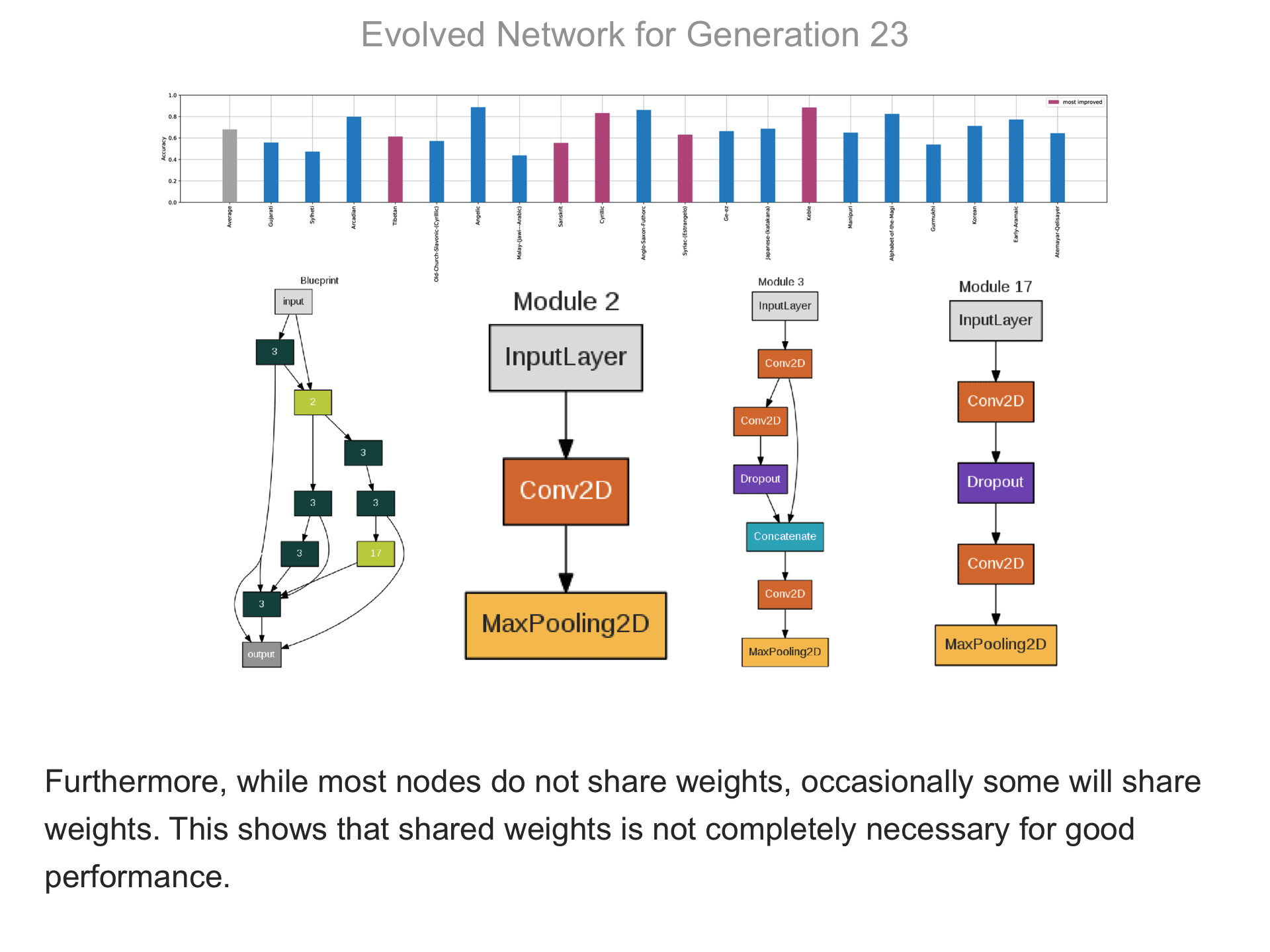
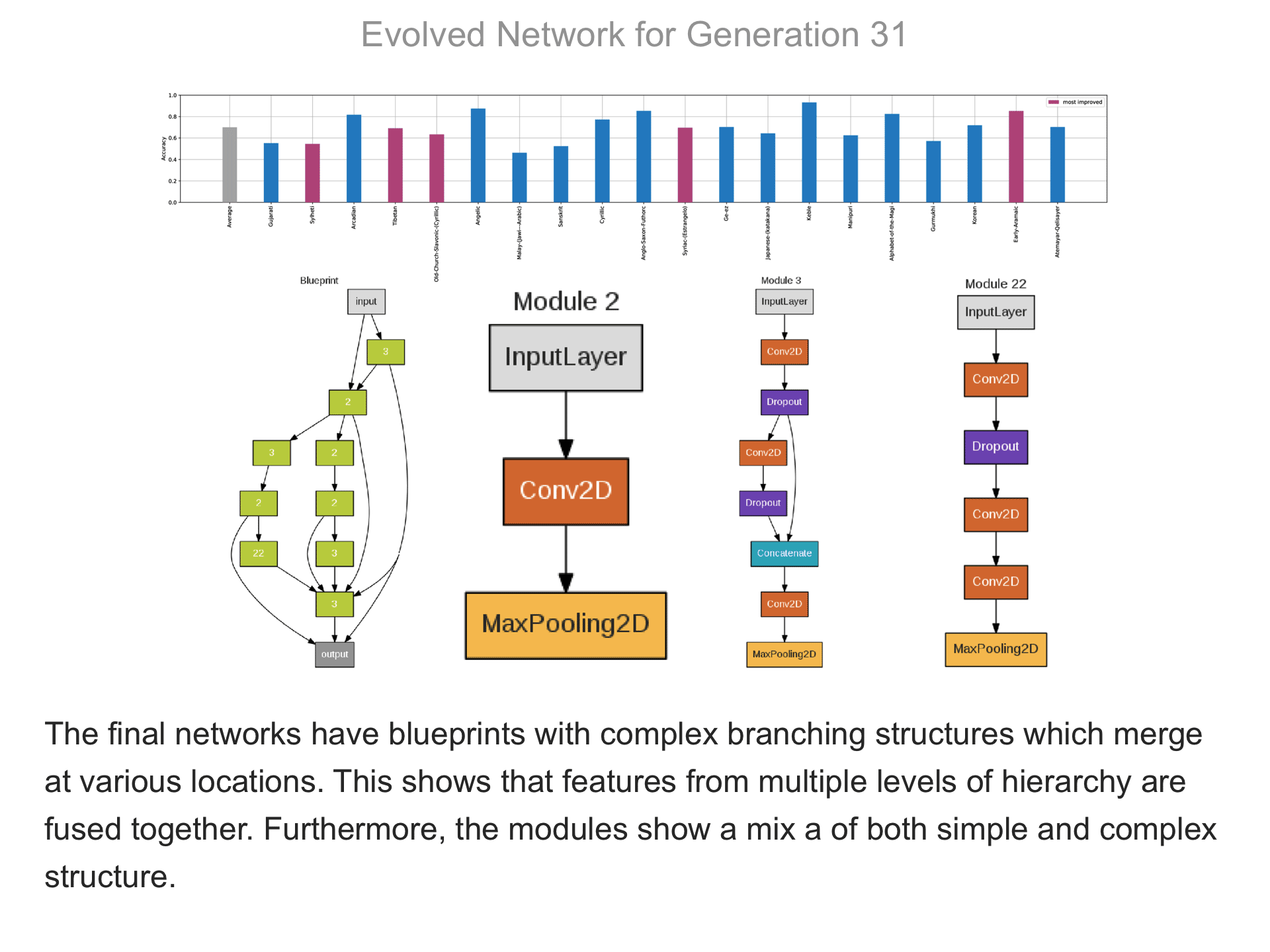
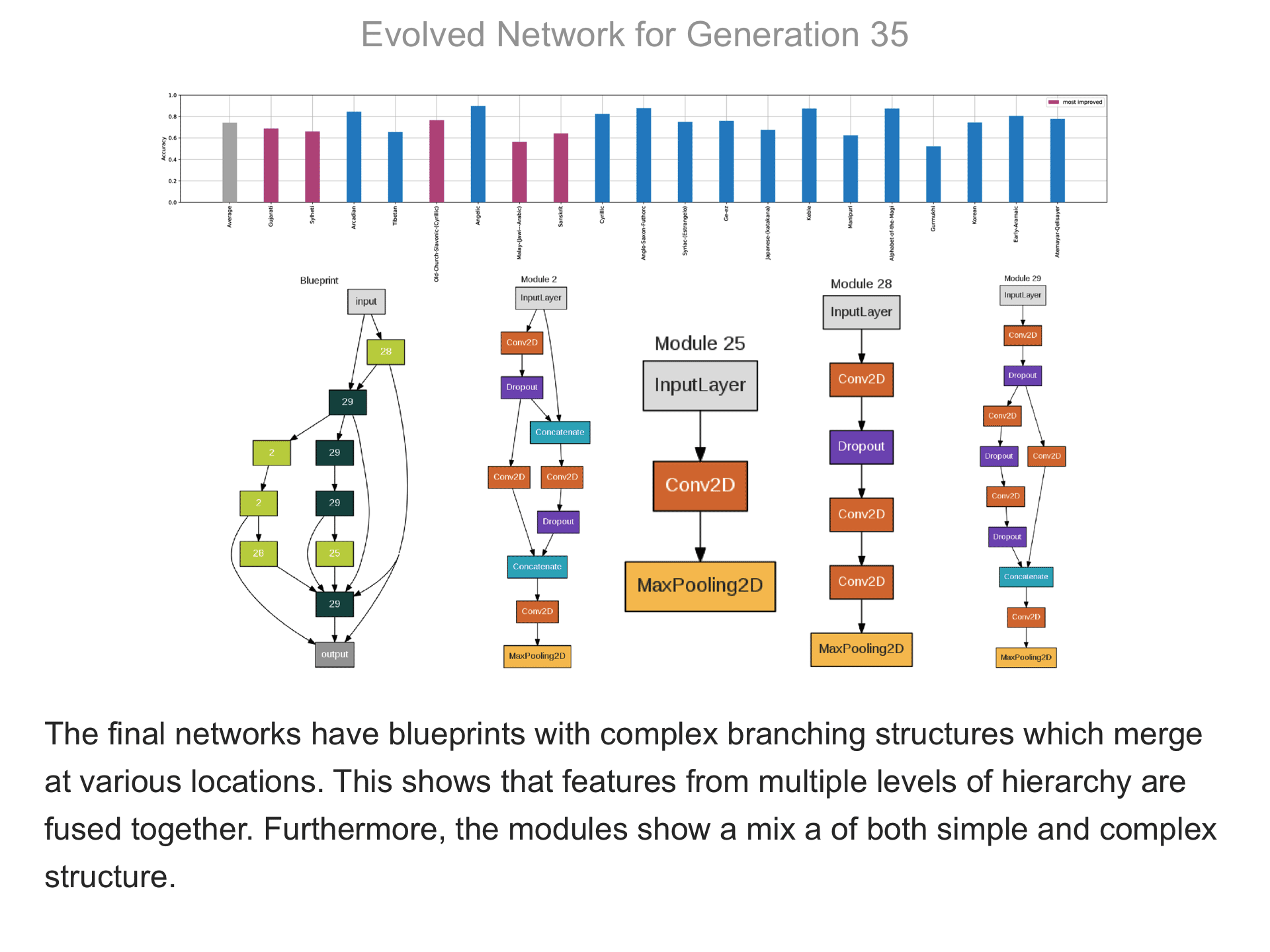
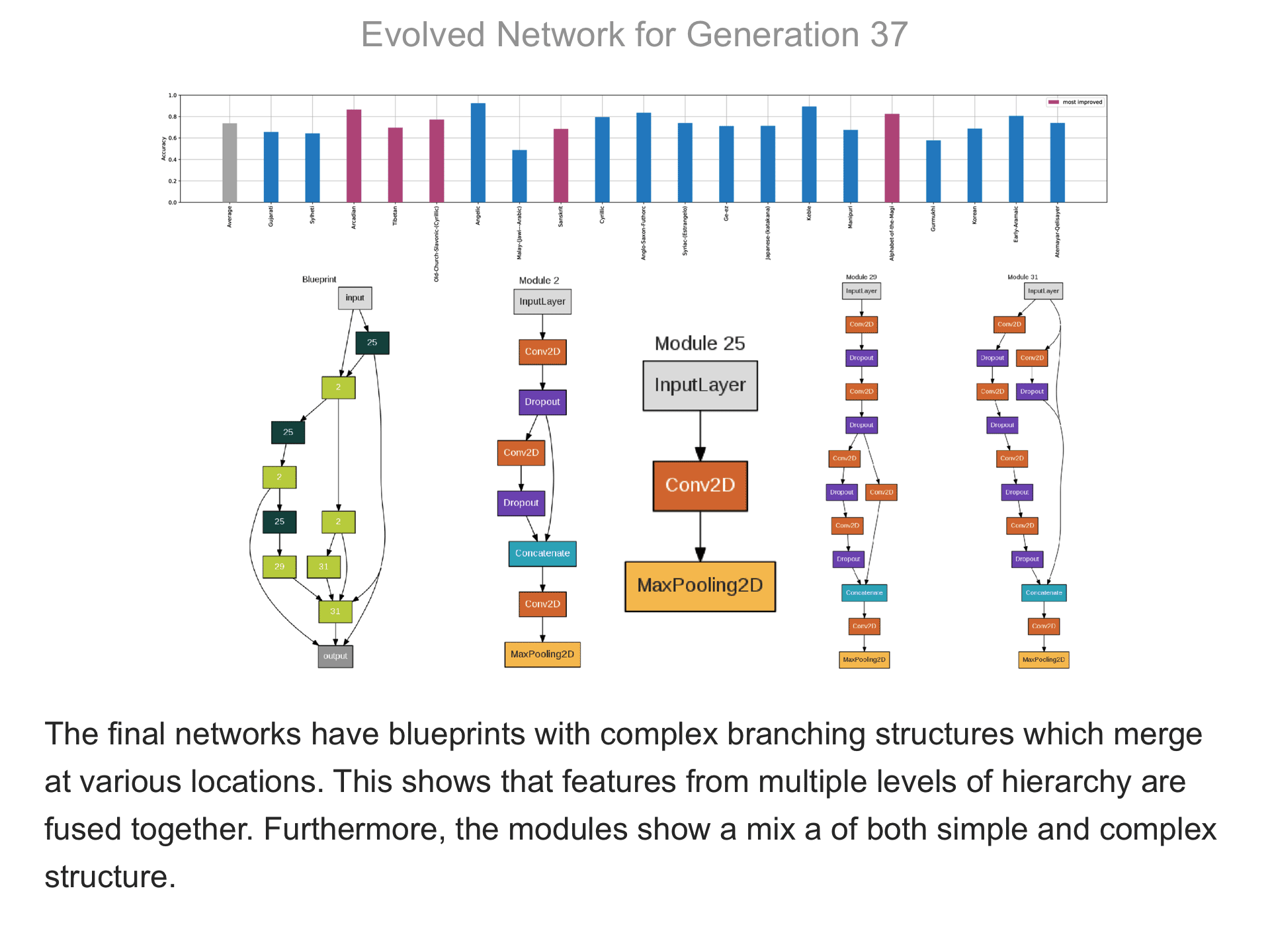
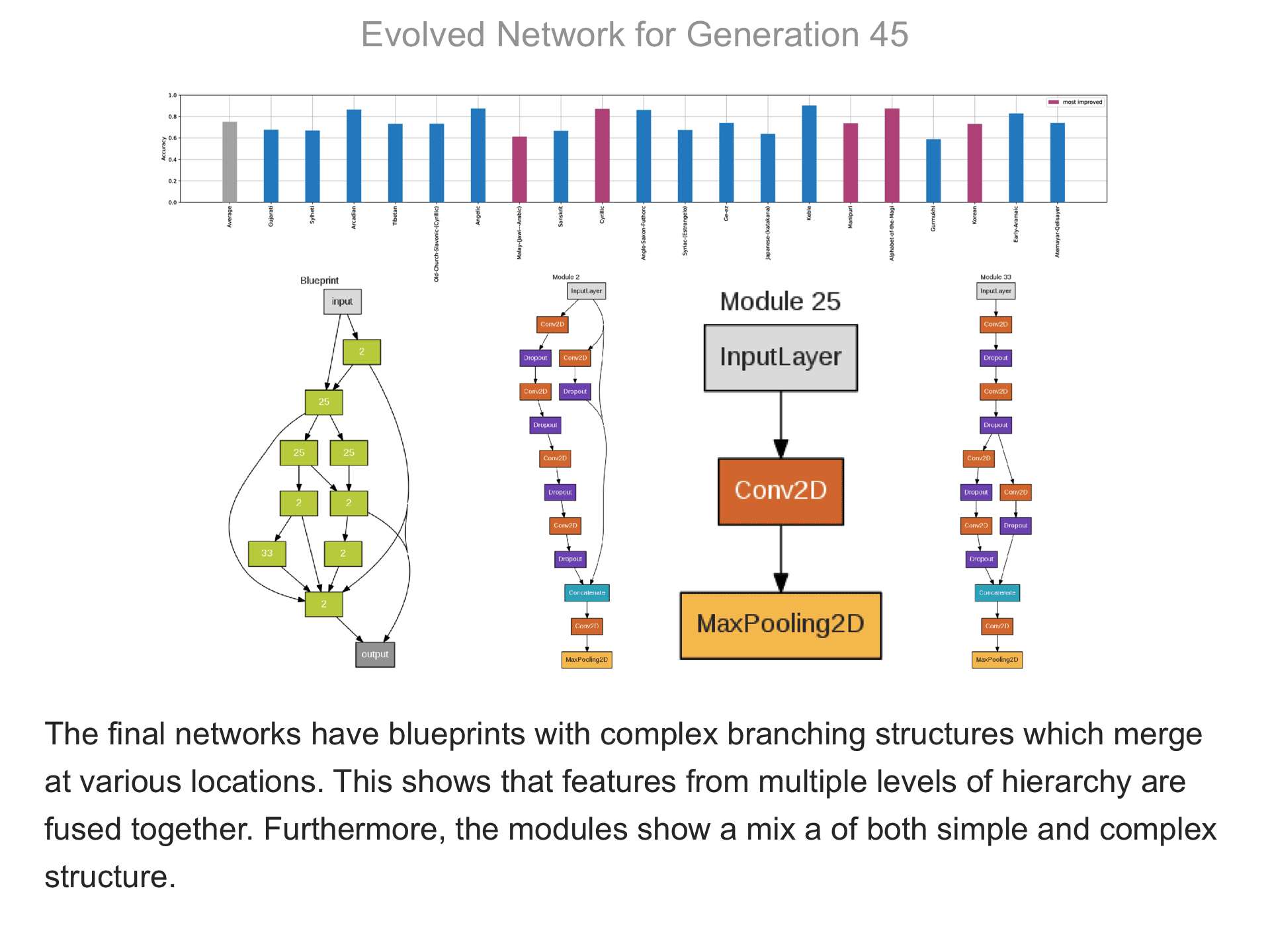
The above demo shows how CMSR constructs complex network architectures for the Omniglot multi-alphabet character recognition task (see Demo 1.3 for a description of this task). Each frame provides a snapshot for the generation identified on top. The bottom part of the frame shows the best blueprint of that generation on the left and the module architectures that the blueprint utilizes on the right. A node whose respective modules have shared weights are indicated by a dark green color. For simplicity, only a single output layer is shown for each blueprint; in reality, there are 20 output layers (one for each alphabet). The top part shows the classification accuracy of the assembled network across 20 different alphabets. The average fitness across all alphabets is shown in the first bar in grey. Note that due to the stochastic nature of evolution, the fitness does not necessarily improve at every generation. The tasks that improve the most from the previous generation are shown in the purple bars. This display thus indicates which tasks are harder to learn than others: for instance, Tibetian (5th bar from the left) and Gukhmuki (4th bar from the right) have complex shapes which make classification hard. The final networks are very complex: they utilize several different kinds of modules, the modules vary in complexity, they have multiple pathways, and occasional weight sharing. Such structures would be very hard to discover by hand, yet they perform very well across the multiple tasks.